
Even under constrained sampling, LLMs can produce syntactically invalid output. In this post I explore why this happens when restricting the maximum number of generated tokens and how to resolve the issue using results from language theory.
LLMs are greate for writing code. However, they tend to generate invalid code. Constrained sampling has emerged to resolve this issue. Impressively, it is able to handle arbitrary Context Free Grammars (CFGs), i.e. most programming language syntax, not only resulting in formally guaranteed correctness but even speedups over unconstrained sampling. [1] Constrained sampling even made it into the popular OpenAI Chat API, in case you wondered how the response_format parameter is implemented.
How constrained LLMs generate syntactically invalid code
These methods have a hidden issue. If you look closely at the results of their evaluation you might have noticed it: The output that constrained models is actually not always free of syntax errors! How can this be? After all, the constraints guarantee that the model output has no syntax errors and always adheres to the given grammar.
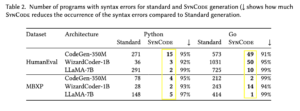
There are two pitfalls two their appraoch:
- The model is limited to output a finite number of tokens. It can happen that the model does not finish generation within this number of tokens. In that case, the method simply aborts and produces an invalid output.
- Even if the model was able to generate an infinite number of tokens, it could enter a loop during generation. This can result in output that is never syntactically correct, even for an unlimited number of generated tokens.
For example imagine we constrain the language model to the syntax of JavaScript. If we constrain it to 30 tokens, even only allowing syntactically correct tokens, we can obtain the following invalid result:1
function foo() {
let one = 1;
let two = 2;
let three = 3;
let four = Unifying constrained sampling and token limits
To resolve this issue, we recall a result from formal language theory: Context-Free-Grammars are closed under intersection with Regular Languages[2]. This means that we can define any regular language (those equivalent to basic regular expressions) and construct a language that only accepts the words that are *both* valid according to the Context-Free Grammar and the Regular Language. This new language is again Context-Free.
To generate such a language for a token limit \(n\)2 we define the regular language \(R_n\). For the token vocabulary T, it is defined as follows: \( R_n = \left\{ x_{1}x_{2}…x_{k} | k \leq n, x_{i} \in T \right\} \). Note that this vocabulary is the vocabulary of the language model tokenizer, not the set of terminals of the Context-Free-Grammar we constrain to.3
If you are not convinced that this is indeed a regular expression, think of the regular expression ({|.join(T)}){,n}, informally written as pseudo-Python format/regex string. I will further provide a proper Python implementation for this expression in the next section.
Our target language to constrain sampling to is then \( L \cap R_n \), where \( L \) is the original CFG we want to constrain to.
The great part is that this generates a CFG that we can feed into any of the existing CFG constraining methods and thus leverage them directly for proper well-formedness guarantees.
Putting it all together in Python
I am using the library PyFormLang[3] to perform the previously described manipulations. Below, you can find an implementation of how to construct the constrained grammar and an example of it applied to the standard example of a CFG, the set of words with balanced 0s and 1s. Of course, this construction applies to any CFG, including the syntax of languages like C or JavaScript.
"""
Construct the CFG that is constrained to at most generating n tokens
"""
from typing import List
from pyformlang.regular_expression import PythonRegex
from pyformlang.regular_expression.python_regex import TRANSFORMATIONS
from pyformlang.cfg import CFG, Terminal
from pyformlang.pda import PDA
SPECIAL_CHARS = set(TRANSFORMATIONS.keys())
def escape_regex(s: str):
for c in SPECIAL_CHARS:
s = s.replace(c, rf"\{c}")
return s
def get_vocab(lang: CFG | PDA):
if isinstance(lang, CFG):
vocab = [x.value for x in lang.terminals]
elif isinstance(lang, PDA):
vocab = [x.value for x in lang.input_symbols]
else:
raise NotImplementedError("wrong type of lang")
return vocab
def constrained_to_n_tokens(
lang: CFG | PDA, n: int, vocab: List[str] = None
) -> PDA | CFG:
if vocab is None:
vocab = get_vocab(lang)
prefix_regex = PythonRegex(("(" + "|".join(vocab) + ")?") * n)
nl = lang.intersection(prefix_regex)
return nl
balanced_01s = CFG.from_text(
"""
S -> ε
S -> 0 S 1
"""
)
def split_to_terms(s: str):
return list(Terminal(c) for c in s)
def test_balanced_token_restricted_to_n():
l5 = constrained_to_n_tokens(balanced_01s, 5)
assert l5.contains(split_to_terms("0011"))
assert l5.contains(split_to_terms("01"))
assert not l5.contains(split_to_terms("000111"))
assert not l5.contains(split_to_terms("00011"))
Limitations and Future Directions
Building this additional CFG is not for free. Concretely, the Regular Language we build has an equivalent deterministic finite automaton with at least \(n\) states. For building the intersection language, we need construct the cross product with the pushdown automata of the CFG, resulting in at least \(n\) states again. While linear, this can quickly become very expensive with normal \(n \ge 1000 \).
More importantly, this grammar needs to be constructed newly for every different \(n\). This is especially expensive because tools like SynCode spent several minutes constructing the token masks for a given CFG – while this process can be easily amortized for fixed grammars, this is not possible when the grammar is constantly changing.
Future research will be necessary to determine the ideal tradeoff for these scenarios, or derive suitable algorithms to reduce the overhead cause by constructing new CFGs, i.e. by reusing parts of grammars or token masks, from smaller \(n\) for larger \(n\).
Conclusion
Existing methods for constrained sampling that operate on Context-Free-Grammars are powerful tools. I show in this post how to leverage these tools for guaranteeing well-formedness even under constraints regarding the number of sampled tokens, using simple intersection with regular languages to generate new CFGs.
Citations
If you end up using these results for your work, please cite as follows
@misc{muendler2024finiteconstrains,
title={Proper Well-Formedness for finite LLM Sampling},
author={Niels Mündler},
year={2024},
url={https://blog.nielstron.de/2024/08/13/proper-well-formedness-for-finite-llm-sampling/}
}Footnotes
- Feel free to check this with the OpenAI tokenizer: https://platform.openai.com/tokenizer ↩︎
- The token limit corresponds exactly to the
max_tokensparameter in the OpenAI Chat API. ↩︎ - The terminals of your context-free language and the terminals of the regular language have to be the same for the intersection to work. The most straightforward way to achieve this is to define the terminals to be all printable characters. ↩︎
References
- [1] Beurer-Kellner et. al. 2024, Guiding LLMs The Right Way: Fast, Non-Invasive Constrained Generation and Ugare et. al. 2024, SynCode: LLM Generation with Grammar Augmentation
- [2] Hopcroft & Ullman 1979, pp.135–136, Theorem 6.5
- [3] Julien 2021, Pyformlang: An Educational Library for Formal Language Manipulation